子查询(Subquery)是嵌套在另一个 SQL 查询内部的查询语句,也称为内层查询(Inner Query) 或嵌套查询。可以出现在 SELECT、FROM、WHERE、HAVING、EXISTS 等子句中,用于提供数据、条件或临时表。就像函数中的“函数调用”,子查询是 SQL 中的“可复用逻辑模块”。可以将复杂问题分解为多个简单步骤,提升逻辑表达能力。
一、子查询(Subquery)基本语法
-- 主查询(外部查询)
SELECT column_list
FROM table1 t1
WHERE condition
AND column1 operator (
-- 子查询(内部查询)
SELECT column_a
FROM table2 t2
WHERE t2.col = t1.col -- 可选:关联条件(相关子查询)
);
| |
|---|
SELECT ... FROM ... WHERE | |
(SELECT ...) | |
operator | 比较运算符:=, >, <, IN, EXISTS, ANY, ALL 等 |
t2.col = t1.col | 若存在此引用,则为“相关子查询”(Correlated Subquery) |
说明:子查询不能独立执行(除非单独提取测试),其生命周期依附于外层查询。多层嵌套时,执行顺序为“由内到外”逐层展开。
二、子查询(Subquery)分类
SQL 子查询可从两个交叉类型进行分类:
| |
|---|
| 按结果形式(结果形态)分类 | ① 标量子查询
② 行子查询
③ 列子查询
④ 表子查询
⑤ EXISTS子查询 |
| 按执行依赖关系(执行模式)分类 | ① 相关(关联)子查询(Correlated Subquery)
② 非相关子查询(Non-Correlated Subquery) |
说明:一个子查询可以既是“标量”又是“相关”的,例如:
SELECT name, (SELECT AVG(salary) FROM emp WHERE dept = e.dept) FROM emp e;
三、标量子查询(Scalar Subquery)
返回单个值(一行一列),常用于与单值比较或作为表达式的一部分。
1、语法结构
SELECT
col1,
(SELECT expr FROM table2 WHERE condition) AS computed_value
FROM table1 t1
WHERE col2 > (SELECT AVG(col3) FROM table3);
- 必须返回0或1行,否则数据库会抛出运行时错误(如:MySQL 的
Subquery returns more than 1 row)。说明:在 MySQL 中,若标量子查询返回多行,使用 = 会报错,但使用 ANY/ALL 可避免(此时实际为列子查询),例如:-- 合法(此时为列子查询)
SELECT * FROM t WHERE col > ANY (SELECT col2 FROM t2);
- 可用于
SELECT、WHERE、HAVING 子句。
2、示例:查询工资高于公司平均工资的员工
-- 示例数据:
-- employees: emp_id, name, dept, salary
SELECT
name, salary
FROM employees
WHERE salary > (
SELECT AVG(salary)
FROM employees -- 子查询独立执行
);
/*
模拟结果:
name | salary
----------|--------
Alice | 80000
Bob | 85000
Eve | 90000
*/
说明:此子查询是“非相关”的,因为它不依赖外部查询中的任何列。
执行过程:
(1)执行子查询:计算 SELECT AVG(salary) FROM employees → 返回(模拟)结果 75000
(2)执行主查询:SELECT name, salary FROM employees WHERE salary > 75000
(3)返回最终结果
3、优化方法
| |
|---|
| 改写为 JOIN | 将标量子查询转为 JOIN + WHERE,避免重复执行 |
| 添加索引 | 在子查询的 WHERE 条件列上建索引(如:salary) |
| 使用窗口函数替代 | 如:AVG(salary) OVER() 避免子查询 |
示例:
-- 优化版本(JOIN)
SELECT e1.name, e1.salary
FROM employees e1
CROSS JOIN (SELECT AVG(salary) AS avg_sal FROM employees) avg_t
WHERE e1.salary > avg_t.avg_sal;
-- 更优方案:使用窗口函数(推荐)
SELECT name, salary
FROM (
SELECT name, salary, AVG(salary) OVER() AS avg_sal
FROM employees
) t
WHERE salary > avg_sal;
4、高阶应用示例
(1)在 SELECT 中返回每个员工的部门平均工资:
SELECT
name,
salary,
(SELECT AVG(salary) FROM employees e2 WHERE e2.dept = e1.dept) AS dept_avg
FROM employees e1;
说明:此为相关标量子查询
(2)与 CASE WHEN 结合实现动态计算:
SELECT
name,
CASE
WHEN dept = 'HR' THEN (SELECT bonus_rate FROM config WHERE dept = 'HR') * salary
ELSE 0
END AS bonus
FROM employees;
四、行子查询(Row Subquery)
返回一行多列,用于多列同时匹配。
1、语法结构
SELECT *
FROM table1
WHERE (col1, col2) = (
SELECT col_a, col_b
FROM table2
WHERE condition
);
- 不支持
>, < 等比较,除非数据库支持复合类型比较,如:部分数据库(如:PostgreSQL)支持对行记录的整体比较(按列顺序逐个比较)。例如:-- PostgreSQL 中合法
SELECT * FROM t WHERE (a, b) > (SELECT c, d FROM t2 WHERE ...);
但这种用法不通用,我们建议避免跨数据库使用。
2、示例:查找与 Alice 工资和部门相同的员工
SELECT name, salary, dept
FROM employees
WHERE (salary, dept) = (
SELECT salary, dept
FROM employees
WHERE name = 'Alice'
);
/*
模拟结果:
name | salary | dept
------|--------|------
Alice | 70000 | HR
John | 70000 | HR
*/
执行过程:
(1)执行子查询:SELECT salary, dept FROM employees WHERE name = 'Alice' → 返回 (70000, 'HR')
(2)主查询遍历 employees 表,对每行检查 (salary, dept) = (70000, 'HR')
(3)匹配成功则返回该行
3、优化方法
| |
|---|
| 改写为 JOIN | |
| 复合索引 | 我们在 (salary, dept) 上建联合索引 |
| 避免全表扫描 | |
示例:
-- 优化版本
SELECT e1.name, e1.salary, e1.dept
FROM employees e1
JOIN employees e2 ON e1.salary = e2.salary AND e1.dept = e2.dept
WHERE e2.name = 'Alice';
4、高阶应用示例
查找每个部门薪资最高的员工(使用相关行子查询):
SELECT *
FROM employees e1
WHERE (salary, dept) IN (
SELECT MAX(salary), dept
FROM employees e2
WHERE e2.dept = e1.dept -- 相关条件
GROUP BY dept
);
注意:某些数据库(如:MySQL)对 (col1, col2) IN (SELECT ...) 支持有限,我们建议改写为 EXISTS。
五、列子查询(Column Subquery)
返回一列多行,用于集合成员判断。
1、语法结构
SELECT *
FROM table1
WHERE col1 IN (
SELECT col_a
FROM table2
WHERE condition
);
- 支持:
IN, NOT IN, ANY, ALL, SOME = ANY 等价于 IN;<> ALL 等价于 NOT IN- 不支持
=、> 等单值比较符(除非用 ANY/ALL)
2、示例:查找财务部和销售部的员工
SELECT name, dept
FROM employees
WHERE dept IN (
SELECT dept_name
FROM departments
WHERE dept_type IN ('Finance', 'Sales')
);
/*
模拟结果:
name | dept
------|--------
Alice | Finance
Bob | Sales
Carol | Finance
*/
执行过程:
(1)执行子查询:SELECT dept_name FROM departments WHERE dept_type IN ('Finance', 'Sales') → 返回集合 {'Finance', 'Sales'}
(2)主查询遍历 employees 表,对每行检查 dept IN ('Finance', 'Sales')
(3)匹配成功则返回该行
3、优化方法
| |
|---|
| 用 EXISTS 替代 NOT IN | NOT IN 对 NULL 敏感,若子查询结果含 NULL,则整个表达式为 UNKNOWN |
| 用 JOIN 替代 IN | |
| 索引 on 子查询列 | 在 departments.dept_name 上建索引 |
说明:若子查询结果包含 NULL,则 NOT IN 会返回无结果(因为 NULL <> 值 的结果是 UNKNOWN,而非 TRUE)。例如:
-- 子查询返回 (1, NULL) 时,以下查询会返回空集
SELECT * FROM t WHERE id NOT IN (SELECT id FROM t2);
而 NOT EXISTS 不受 NULL 影响,因此我们推荐用 NOT EXISTS 替代 NOT IN。
示例:
-- 优化版本(JOIN)
SELECT e.name, e.dept
FROM employees e
JOIN departments d ON e.dept = d.dept_name
WHERE d.dept_type IN ('Finance', 'Sales');
4、高阶应用示例
(1)查找工资高于任意财务部员工的员工:
SELECT name, salary
FROM employees
WHERE salary > ANY (
SELECT salary
FROM employees
WHERE dept = 'Finance'
);
(2)使用 ALL 实现“全集匹配”:
-- 查找工资高于所有财务部员工的员工
SELECT name, salary
FROM employees
WHERE salary > ALL (
SELECT salary
FROM employees
WHERE dept = 'Finance'
);
六、表子查询(Table Subquery / Derived Table)
返回多行多列,作为临时表使用,必须用 AS alias 命名。
1、语法结构
SELECT t.col1, t.col2
FROM (
SELECT col_a, col_b
FROM table1
WHERE condition
) AS t
WHERE t.col1 > value;
2、示例:统计各部门平均工资并筛选
SELECT dept, avg_salary
FROM (
SELECT dept, AVG(salary) AS avg_salary
FROM employees
GROUP BY dept
) AS dept_avg
WHERE avg_salary > 60000;
/*
模拟结果:
dept | avg_salary
-------------|------------
Engineering | 75000
Sales | 68000
*/
执行过程:
(1)执行子查询:SELECT dept, AVG(salary) FROM employees GROUP BY dept → 生成临时表:
dept | avg_salary
--------------|------------
Engineering | 75000
Sales | 68000
HR | 55000
(2)主查询从临时表中筛选:WHERE avg_salary > 60000
(3)返回最终结果
3、优化方法
示例:
-- 使用 CTE 更清晰(推荐)
WITH dept_avg AS (
SELECT dept, AVG(salary) AS avg_salary
FROM employees
GROUP BY dept
)
SELECT * FROM dept_avg WHERE avg_salary > 60000;
4、高阶应用示例
多层聚合分析:
WITH monthly_avg AS (
SELECT dept, YEAR(hire_date) y, MONTH(hire_date) m, AVG(salary) avg_sal
FROM employees GROUP BY dept, y, m
)
SELECT dept, AVG(avg_sal) annual_avg
FROM monthly_avg
GROUP BY dept;
七、EXISTS 子查询(Existential Subquery)
用于判断是否存在满足条件的行,返回布尔值(TRUE/FALSE)。
1、语法结构
SELECT *
FROM table1 t1
WHERE EXISTS (
SELECT 1 -- 推荐用 1,不查具体列
FROM table2 t2
WHERE t2.ref = t1.id
);
EXISTS 只关心“是否存在”,不关心返回什么(SELECT * 也可,但 SELECT 1 更高效)NOT EXISTS 常用于“差集”查询(如:“无订单客户”)- 支持短路求值(Short-circuit evaluation):一旦找到匹配行即返回 TRUE
2、示例:查找有订单的客户
SELECT customer_name
FROM customers c
WHERE EXISTS (
SELECT 1
FROM orders o
WHERE o.customer_id = c.customer_id
);
/*
模拟结果:
customer_name
-------------
Alice
Bob
David
*/
执行过程:
(1)主查询从 customers 表中读取第一行(如:Alice)
(2)执行子查询:SELECT 1 FROM orders WHERE customer_id = 'Alice'
- 若找到至少一行 →
EXISTS 返回 TRUE → 返回该客户
(3)对 customers 表中每一行重复上述过程
3、优化方法
| |
|---|
| 用 EXISTS 替代 IN | 当内表大、外表小时,EXISTS 更快(利用索引快速命中) |
| 用 IN 替代 EXISTS | |
| 索引 on 关联列 | 在 orders.customer_id 上建索引 |
| 避免 SELECT | |
4、高阶应用示例
(1)查找没有订单的客户(NOT EXISTS):
SELECT c.customer_name
FROM customers c
WHERE NOT EXISTS (
SELECT 1 FROM orders o WHERE o.customer_id = c.customer_id
);
(2)多层存在性判断(嵌套 EXISTS):
-- 查找有至少一个订单且订单中有高价商品的客户
SELECT c.name
FROM customers c
WHERE EXISTS (
SELECT 1 FROM orders o WHERE o.cust_id = c.id
AND EXISTS (
SELECT 1 FROM order_items oi WHERE oi.order_id = o.id AND oi.price > 1000
)
);
八、相关(关联)子查询(Correlated Subquery)
子查询的执行依赖外部查询的列,必须为外部每一行重新执行。其特点有:性能较差(O(n×m),n为外层行数,m为内层平均行数);逻辑清晰,表达能力强;常用于 EXISTS、SELECT、WHERE。
1、示例:
-- 为每个员工计算其部门平均工资
SELECT
name,
salary,
(SELECT AVG(salary) FROM employees e2 WHERE e2.dept = e1.dept) AS dept_avg
FROM employees e1;
执行过程:
(1)主查询读取 employees 第一行(如:Alice, HR, 70000)
(2)执行子查询:SELECT AVG(salary) FROM employees WHERE dept = 'HR' → 返回 60000
(3)返回该行并附上 dept_avg = 60000
(4)对下一行重复(如:Bob, Engineering, 80000)→ 子查询变为 WHERE dept = 'Engineering'
2、优化建议
- 使用数据库的 子查询提升(Subquery Unnesting) 优化(如:Oracle、PostgreSQL)
3、按结果形式(结果形态)分类的五种子查询是否可能是“关联子查询”?
| | |
|---|
| 标量子查询 | | SELECT name, (SELECT AVG(salary) FROM emp e2 WHERE e2.dept = e1.dept) FROM emp e1; |
| 行子查询 | | SELECT * FROM emp e1 WHERE (dept, salary) = (SELECT dept, MAX(salary) FROM emp e2 WHERE e2.dept = e1.dept); |
| 列子查询 | | SELECT * FROM emp e1 WHERE salary > ANY (SELECT salary FROM emp e2 WHERE e2.manager = e1.id); |
| 表子查询 | | SELECT * FROM (SELECT dept, AVG(salary) FROM emp GROUP BY dept) t;
必须独立执行生成临时表,不能引用外部列,因此不能是关联子查询。 |
| EXISTS 子查询 | | SELECT * FROM emp e1 WHERE EXISTS (SELECT 1 FROM orders o WHERE o.emp_id = e1.id); |
特别注意:表子查询(FROM 子句中的子查询)几乎不可能是关联的,因为数据库必须先执行它来生成临时表,而此时外部查询尚未开始。备注:为什么说几乎不可能?少数数据库(如:Oracle 12c+)支持 “关联派生表”(Correlated Derived Tables),允许表子查询引用外部列,但这是特殊语法且不推荐使用(会导致性能问题)。
结论:
- “关联子查询”是一种执行模式,它可以出现在多种结果类型的子查询中。
- 除了 表子查询(FROM 子句)外,其他类型的子查询:标量子查询、行子查询、列子查询 和 EXISTS 子查询 都可能是关联子查询
九、性能优化建议
| | |
|---|
| JOIN | |
| EXISTS | |
| IN | |
| | |
| CTE(Common Table Expression) | |
| | |
能用 JOIN 和 CTE 的,尽量不用子查询。说明:现代数据库优化器(如:PostgreSQL、Oracle)通常会将等价的子查询自动转换为 JOIN 执行(即 “子查询展开” 优化),因此简单子查询与 JOIN 的性能差异可能很小。但复杂子查询(尤其是多层嵌套或相关子查询),我们仍建议手动改写为 JOIN 或 CTE,提升可读性和优化器处理效率。
性能排序(一般情况):JOIN ≈ CTE > EXISTS > IN > 相关子查询 > 多层嵌套子查询
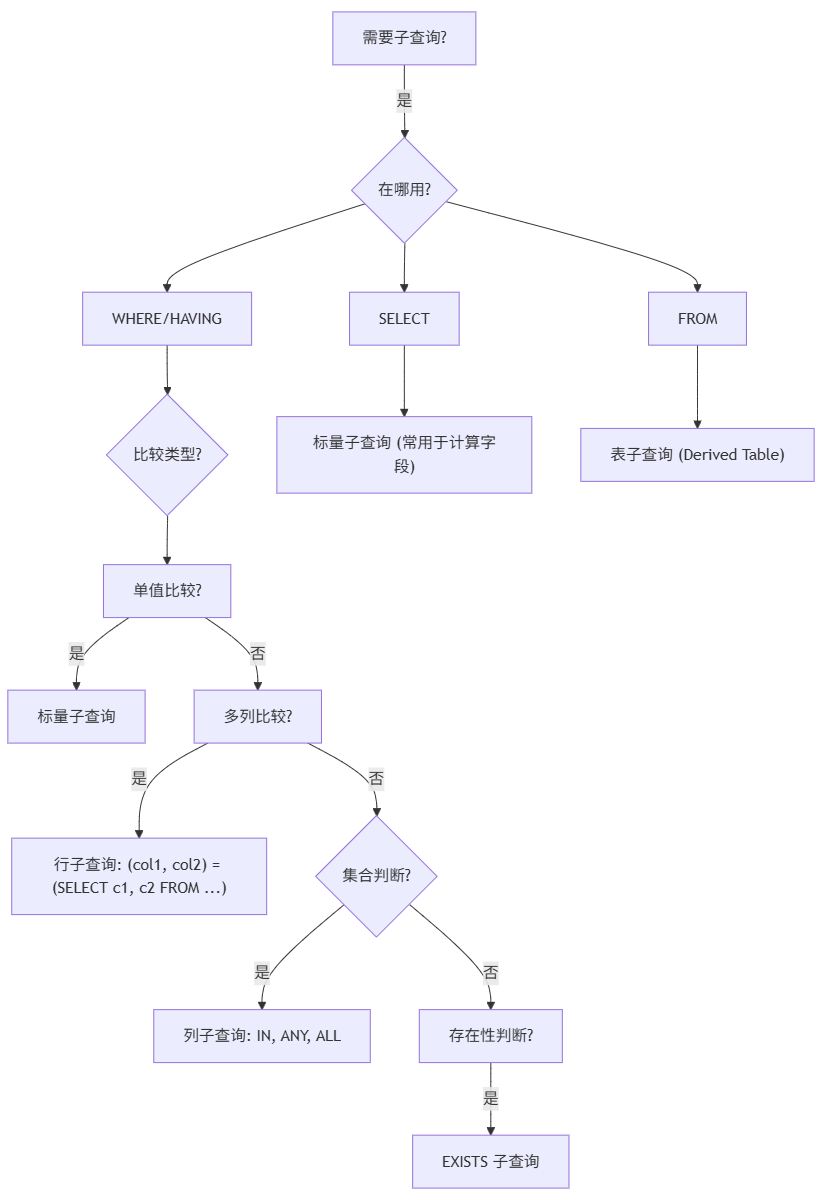
十、总结:子查询使用决策树
graph TD
A[需要子查询?] -->|是| B{在哪用?}
B --> C[WHERE/HAVING]
B --> D[SELECT]
B --> E[FROM]
C --> F{比较类型?}
F --> G[单值比较?]
G -->|是| H[标量子查询]
G -->|否| I[多列比较?]
I -->|是| J["行子查询: (col1, col2) = (SELECT c1, c2 FROM ...)"]
I -->|否| K{集合判断?}
K -->|是| L[列子查询: IN, ANY, ALL]
K -->|否| M[存在性判断?]
M -->|是| N[EXISTS 子查询]
D --> O["标量子查询 (常用于计算字段)"]
E --> P["表子查询 (Derived Table)"]
阅读原文:原文链接
该文章在 2025/8/25 13:24:36 编辑过






 400 186 1886
400 186 1886