Redis凭什么用单线程“干翻”了全世界?
当前位置:点晴教程→知识管理交流
→『 技术文档交流 』
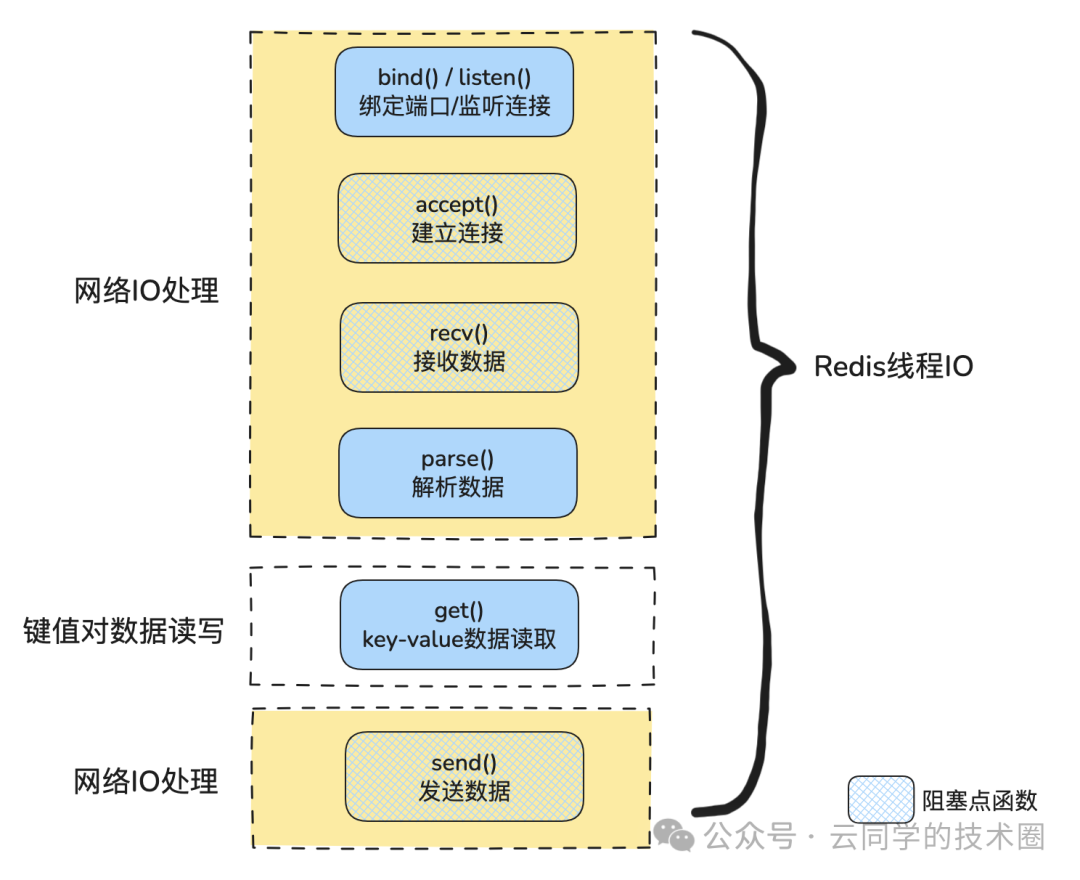
Redis (Remote Dictionary Server),即远程字典服务,是一个开源的、使用 C 语言编写的、高性能的内存键值 (Key-Value) 数据库。 在工程实践中,想必你也或多或少都接触过它,但是,Redis作为“单线程”应用,为什么它会这么快?你可能会说因为用了内存,其实这只是其中一点,下边让我们一起揭晓答案吧。 这里要特别指出的是,Redis的“单线程”,主要是指网络IO和实际的key-value读写是由一个线程完成的,但是,持久化、数据删除、AOF重写等,其实还是由额外的线程执行的。 并且,从Redis 6.0开始,网络IO也采用多线程,只有读写命令是用单线程处理。 01 “3个因素”造就了Redis的高性能 Redis以其出色的性能和灵活性,常被称为数据处理领域的“瑞士军刀”,常用于缓存、会话存储、消息队列、分布式锁等场景。 Redis高性能的根因可以归纳为以下3点: 内存为王-物理定律上的优势 这是 Redis 高性能的基石,Redis数据存放在内存中,是它与其他基于磁盘的数据库(如 MySQL, PostgreSQL, MongoDB)的重要区别之一。 极致的数据结构 Redis内部对哈希表、跳表等数据结构做了特别优化,会根据数据的大小和类型,动态选择最优的内部编码,实现“空间换时间”或“时间换空间”,极大地减小了网络开销和客户端的压力。 高效的IO模型 采用了IO多路复用机制,使其在网络 IO 操作中能并发处理大量的客户端请求,实现高吞吐率。 前两点的物理内存的优势和优化的数据结构,比较好理解,今天我们重点说的是Redis的IO多路复用模型。 02 为什么要用IO多路复用? 理解IO模型前,我们来看一下,IO多路复用到底能解决什么问题? 一句话概括: IO多路复用(I/O Multiplexing) 是一种机制,它允许一个单独的进程(或线程)监视多个文件描述符(File Descriptor, FD),一旦其中任何一个FD准备好进行IO操作(比如可读、可写或出现异常),该机制就会通知相应的进程。 为了更好地理解,我们用一个经典的场景举例: 一个网络服务器需要同时处理成百上千个客户端连接,会面临的3种选择: 1、阻塞IO + 每次连接一个新的进程/线程模型 工作方式: 每当一个新客户端连接进来,服务器就创建一个新的进程或线程专门为它服务。这个线程在等待客户端数据时,会调用read()或recv(),然后阻塞(block),直到数据到达。 缺点: 资源消耗巨大: 每个进程/线程都需要消耗内存(如栈空间)和CPU资源。成千上万个连接就意味着成千上万个线程,系统根本无法承受。 上下文切换开销大: CPU需要在这些大量的线程之间频繁切换,这本身就是一笔巨大的开销,导致实际用于处理业务逻辑的时间大大减少。 2、非阻塞IO + 忙轮询(Busy-Polling) 工作方式: 将每个连接的IO操作设置为非阻塞模式。然后用一个循环,不断地去轮询(“询问”)每一个连接:“你有数据要读吗?” “你可以写数据了吗?” 缺点: CPU空转: 即使大部分连接都没有事件发生,循环也会一直运行,不停地做无用功,导致CPU使用率100%,造成巨大的浪费。 3、IO多路复用 工作方式: 应用进程将一批需要监视的文件描述符(代表所有客户端连接)“注册”给内核; 应用进程调用一个阻塞函数(如select(), poll(), epoll_wait()),然后自己就去“睡觉”了,不占用CPU; 内核开始作为“代理”或“管家”,在底层持续监视这些FD。当任何一个或多个FD准备就绪(例如,某个客户端发来了数据),内核就会唤醒正在“睡觉”的应用进程; 应用进程被唤醒后,返回的结果会明确告诉它哪些FD已经准备好了; 应用进程只需要处理那些真正准备就绪的连接,进行读写操作。 优势: IO多路复用就是为了解决以上两个模型的痛点而生的。 它引入了一个“代理”或“协调者”(即内核中的select, poll, epoll等机制)。 这样,一个线程就能高效地管理海量的连接,既避免了多线程的资源和切换开销,也避免了忙轮询的CPU浪费。 03 Linux 3种IO多路复用实现方式 Linux系统为我们提供了3种主要的IO多复用API,即经常能看到的select、poll、epoll。 1、select select 是最早的、最经典的多路复用实现,遵循POSIX标准,因此可移植性最好。 工作原理: 创建一个fd_set(一个位图结构),把要监视的FD对应位置为1; 调用select( )函数,将这个fd_set从用户空间拷贝到内核空间; 内核遍历所有被监视的FD,检查它们的状态; select( )返回后,内核会将准备就绪的FD对应位置为1,未就绪的置为0,再将修改后的fd_set拷贝回用户空间; 用户进程需要再次遍历整个fd_set,找出哪些FD是准备就绪的。 缺点: 文件描述符数量限制: fd_set的大小是固定的(通常是1024),限制了能监视的FD数量。 重复拷贝开销: 每次调用select都需要在用户空间和内核空间之间来回拷贝fd_set,连接数越多,开销越大。 线性扫描开销: 内核和用户进程都需要遍历整个FD集合来查找就绪的FD,效率是O(n),其中n是监视的FD总数。即使只有一个FD就绪,也得全部扫一遍。 2、poll poll 是对select的改进,解决了FD数量限制的问题。 工作原理: 它使用一个pollfd结构体数组来代替fd_set。这个数组没有固定大小限制,可以动态分配。 工作流程与select类似,仍然需要将整个pollfd数组从用户空间拷贝到内核空间,并且返回后需要遍历数组来查找就绪的FD。 优点: 没有FD数量限制,只受限于系统资源。 缺点: 仍然存在重复拷贝和线性扫描的开销,性能问题在连接数巨大时依然存在。 3、epoll(Event Poll) epoll 是Linux下对select和poll的重大改进,是目前公认的在Linux上实现高性能网络服务器的首选。Nginx、Redis等都使用了它。 工作原理: epoll 的设计思想完全不同,它引入了三个核心函数: epoll_create( ) 在内核中创建一个epoll实例(可以想象成一个事件中心),返回一个代表该实例的FD。这个实例内部包含一个红黑树(用于快速查找FD)和一个就绪链表(用于存放已就绪的FD)。 epoll_ctl( ) 用于向epoll实例中添加、修改或删除要监视的FD。当注册一个FD时,内核会将这个FD和一个回调函数关联起来。当该FD就绪时,内核会自动调用这个回调函数,将其放入就绪链表中。 epoll_wait( ) 阻塞等待,直到epoll实例的就绪链表非空。一旦有就绪的FD,epoll_wait就会被唤醒,并直接返回就绪FD的列表。 优点: 没有FD数量限制。 避免重复拷贝: epoll_ctl将FD注册到内核后,就不需要每次调用epoll_wait时都重复拷贝FD列表了。它基于事件驱动,由内核来记录和跟踪FD状态。 效率极高: epoll_wait返回时,直接返回的就是就绪的FD列表,用户进程无需再遍历整个集合。其时间复杂度是O(1),与监视的FD总数无关,只与活跃的FD数量有关。 04 Redis的IO模型 1、Redis网络IO处理中的核心步骤 以一个GET请求为例,Redis 网络IO处理大概有如下过程: 网络IO处理流程
2、非阻塞模式设置 上述函数中, bind() 绑定地址和端口,是本地操作,几乎瞬间完成。 listen() 将套接字转换为监听状态,也是一个本地内核操作,立即返回。 parse()和get() 都偏向于应用层逻辑。 但在默认情况下,accept()、recv()、send()是阻塞模式的,也就是说,当 Redis 监听到一个客户端有连接请求,但一直未能成功建立起连接时,会阻塞在 accept() 函数这里,导致其他客户端无法和 Redis 建立连接。类似的,当 Redis 通过 recv()/send() 从一个客户端读取或返回数据时,如果数据一直没有到达或返回,Redis 也会一直阻塞在 recv()/send()。 不过,幸运的是,socket 网络模型本身支持非阻塞模式。 在网络 I/O 处理中,将套接字(Socket)设置为非阻塞模式,主要影响的是那些需要“等待”网络事件的函数。 一个套接字一旦通过 fcntl() 或 ioctl() 设置为非阻塞模式,所有作用于该套接字上的 I/O 函数都会变成非阻塞的。 (1)accept() - 接受连接
(2)recv() - 接收数据
(3)send() - 发送数据
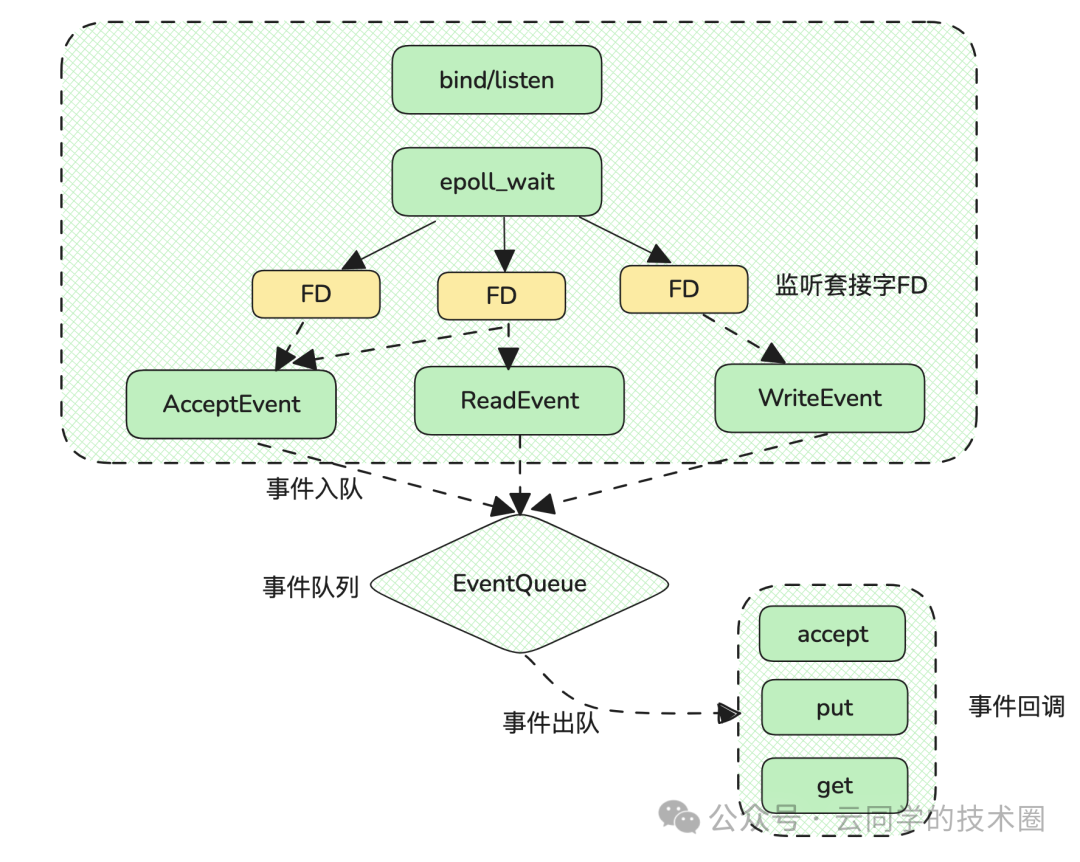
3、Redis实现 Redis的epoll机制 毫无疑问,Redis采用select/epoll模式来提升进行IO操作。 上图中的多个 FD 就是多个套接字。Redis 网络框架调用 epoll 机制,让内核监听这些套接字。此时,Redis 线程不会阻塞在某一个特定的监听或已连接套接字上,也就是说,不会阻塞在某一个特定的客户端请求处理上。正因为此,Redis 可以同时和多个客户端连接并处理请求,从而提升并发性。 为了在请求到达时能通知到 Redis 线程,select/epoll 提供了基于事件的回调机制,即针对不同事件的发生,调用相应的处理函数。 那么,回调机制是怎么工作的呢? 其实,select/epoll 一旦监测到 FD 上有请求到达时,就会触发相应的事件。 这些事件会被放进一个事件队列,Redis 单线程对该事件队列不断进行处理。 这样一来,Redis 无需一直轮询是否有请求实际发生,这就可以避免造成 CPU 资源浪费。同时,Redis 在对事件队列中的事件进行处理时,会调用相应的处理函数,这就实现了基于事件的回调。 05 小结 Redis之所以是性能王者,来自于使用了“物理优势”的内存、极致的数据结构和高效的IO模型。 IO模型的高效,是因为它采用了内核的epoll机制,使得Redis无需“关注”IO等待,可以持续不断地对事件队列进行处理,所以能及时迅速地响应客户端请求,达到性能最优。 阅读原文:原文链接 该文章在 2025/8/25 13:07:18 编辑过 |
关键字查询
相关文章
正在查询... 



|


 400 186 1886
400 186 1886